.png)

Eedi helps teachers uncover and address misconceptions in maths. Our diagnostic questions are written so that every wrong answer points to a specific misconception, which means teachers get a clear picture of how their students are actually thinking.
Our latest paper, Knowing When to Defer: Selective Prediction for Responsible Knowledge Tracing, grew out of a question we kept running into internally: what should a model do when it isn't sure about a student’s future performance prediction? Our answer is that it should say so, and escalate it to a teacher to decide instead.
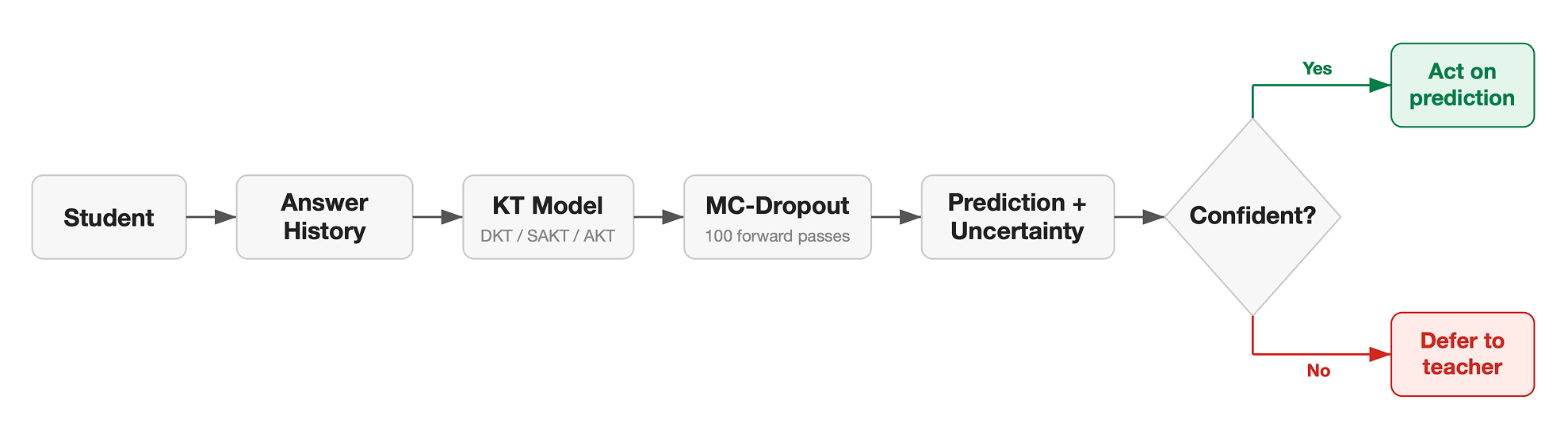
Knowledge Tracing (KT) models watch a student work through questions over time, track what they get right and wrong, and predict how they'll do on the next one. Platforms use these predictions to recommend questions, detect misconceptions, and personalise learning paths. But most KT models only produce a point prediction. They don't say how confident they are in it, which means there's no way to tell a strong prediction from a wrong one.
Having a confidence estimate is important for deploying systems that directly interact with students. Say a student is working through a quiz on multiplying fractions. The model predicts they'll get the next question right, but the student ends up adding the numerators and denominators instead. This is a misconception that the model failed to flag, given the student’s performance on previously answered questions. If we look inside the model, we find it was never particularly sure about that prediction. The confidence was low. But because traditional KT systems only output a single answer and discard everything else, that hedging is invisible.
The misconception goes undetected, and this kind of silent failure compounds. A student gets routed down a learning path built on an assumption of understanding they don't have. The misconception not only persists, it gets reinforced by every subsequent question that builds on it.
We wanted to add uncertainty estimation to existing KT models without rebuilding them. The technique we use is Monte Carlo Dropout (MC-Dropout).
Dropout is a standard trick in neural network training: we randomly switch off parts of the network on each training step to stop it from overfitting. Normally we turn dropout off when we deploy the model. MC-Dropout keeps dropout on at prediction time and runs the model 100 times, each time with a different random subset of the network active. Each pass gives a slightly different prediction.
When the model is confident about a student, those 100 predictions cluster together. When it isn't, they spread out. We quantify that spread using entropy:
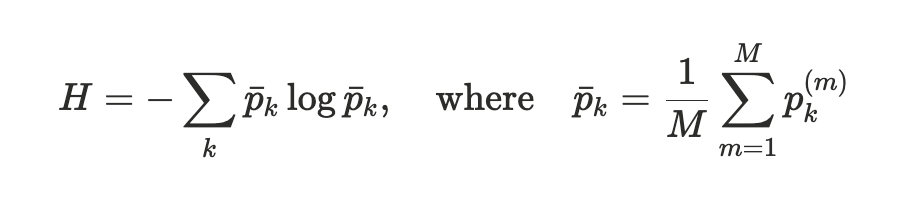
Here k indexes the two possible outcomes (correct or incorrect). Each dropout pass m produces its own probability estimate for each outcome, pₖ⁽ᵐ⁾. We average these across all M passes to get the mean predicted probability p̄ₖ. When both outcomes end up with similar mean probabilities (close to 50/50), entropy is high and the model is uncertain. When one outcome dominates, entropy is low and the model is confident. The model conditions all of this on the next question and the student's full interaction history up to that point. Each past interaction records which question was asked, which knowledge components it tested, and how the student responded.
Low entropy means the passes agree, so the model is confident. High entropy means they disagree, and the prediction is more likely to be wrong.
Because MC-Dropout only changes inference behaviour, we were able to apply it to three widely-used existing KT architectures without modifying their trained weights: DKT, which uses recurrent networks; SAKT, which uses self-attention; and AKT, which adds context-aware attention with a forgetting mechanism. We thus use the same models and the same parameters, but add an extra uncertainty readout on top.
Before building anything on top of the uncertainty signal, we needed to know whether it actually means something. Across all three architectures, misclassified predictions carry significantly higher entropy than correct ones, which confirms that the model really is less sure when it's about to get something wrong.
.png)
With a meaningful uncertainty signal, we used it as a filter. The idea, which we call selective prediction, is straightforward: rank all predictions by how uncertain the model is and set aside the under-confident ones for a teacher to handle instead.
Deferring the 20% most uncertain predictions lifts accuracy by 2.3 to 3.0 percentage points, AUC by 1.9 to 2.4 pp, and F1 by 1.4 to 4.3 pp across all three architectures, with no retraining needed. The 95% bootstrap confidence intervals are tight (±0.13 pp for accuracy, ±0.10 pp for AUC, ±0.20 pp for F1).
.png)
The improved metrics are encouraging to us, but two harder questions matter more for real deployment. (1) Is the model deferring the predictions it should defer? (2) And is it disproportionately giving up on weaker students?
For targeting, we find that the deferred set has a 1.45x to 1.60x higher error rate than the kept set. We also checked this within each quartile of question difficulty, since a natural concern is that the model might simply be deferring hard questions. We find that the targeting holds at every difficulty level, and is actually strongest on the hardest questions (2.3x to 2.5x error ratio), which is where misconceptions tend to concentrate.
On fairness: the abstention rate stays between 16% and 23% across all four student-ability quartiles, close to the 20% baseline we'd expect from uniform random deferral. The model isn't quietly giving up on struggling learners.
.png)
A reasonable critique is: is MC-Dropout really necessary here? Item Response Theory (IRT) is well established in EdTech deployment and already provides a sense of how ambiguous a prediction is, based on student ability and question difficulty.
When we ran them head-to-head on the same selective prediction task, a calibrated 2-parameter IRT model lifted AUC by just 0.41 to 0.46 pp at 80% coverage, compared to 2.0 to 2.4 pp from MC-Dropout variance. That's roughly five times the signal. The neural network's uncertainty is clearly tracking something that IRT, with its two parameters per question, has no way of representing.
.png)
That gap raised an obvious follow-up question of what MC-Dropout is actually responding to, if not the things IRT already measures. To find out, we ran a variance decomposition. We regressed each model's BALD score (a measure of epistemic uncertainty) against what classical psychometrics can offer: question difficulty, student ability, IRT outcome ambiguity, and whether the student had previously seen the relevant topic, subtopic, and construct.
Under a linear model, all of that together explains less than 4% of the variance. Even a cross-validated random forest, which we included to give the classical features every possible advantage, tops out at 23%. That leaves 77% to 90% of the MC-Dropout signal with no classical explanation.
The model is responding to something in each student's particular sequence of interactions, patterns in how they've been answering over the last 100 questions, that two-parameter psychometric models can't encode. No coverage heuristic or IRT calibration layer can replicate it, because the information only exists inside the neural network's learned representations.
When a KT model decides what a student sees next on a platform, wrong predictions have real consequences. Overestimate a student's understanding and we skip them past material they haven't grasped. Underestimate it and we waste their time on things they already know. If we miss a misconception, it can compound before anyone notices.
Selective prediction gives us a way to catch the riskiest calls before they reach the student. Concretely, a deployment might work like this: predictions where the model is confident feed directly into the recommendation engine, while the uncertain 20% get routed to a teacher review queue or trigger a fallback diagnostic question. The teacher's time then goes where it's most needed.
What this work also shows is that the model's own uncertainty, extracted via MC-Dropout, outperforms every other signal we tested for identifying risky predictions. Question difficulty and student ability cannot catch this signal. The useful information is inside the model in the form of uncertainty of predictions.
Everything reported here is measured on held-out validation data, so the natural next step is a live classroom trial where we can see whether selective prediction actually improves student outcomes and reduces teacher workload, not just model metrics.
Beyond that, we also want to extend the framework to predict which specific wrong answer a student will choose, not just whether they'll get the question right. This would tie the uncertainty signal directly to individual misconceptions.
This paper has been accepted at the Festival of Learning 2026 in Seoul, Korea. The full paper is available here: Knowing When to Defer: Selective Prediction for Responsible Knowledge Tracing.