

At Eedi we believe that timely identification of student misconceptions is key to improving student learning outcomes. Misconceptions are recurring patterns of misunderstanding that lead to predictable mistakes. As a result identifying misconceptions before the errors compound is of importance to improve student learning outcomes.
At Eedi, we use diagnostic questions, which are questions written in such a way that each incorrect answer attempts to uncover a specific misconception. As a result when a student chooses an incorrect answer it suggests that they may have the associated misconception tagged to that answer. Despite this, students can choose incorrect answers for other reasons than having a specific misconception, e.g., slips, disengagement, and guessing. We are interested in building a system that allows us to identify the true misconception a student has.
In this work we sought to create a solution that allows us to uncover student misconceptions from student-tutor dialogues instead. Student-tutor dialogues provide a richer source of information about the students current understanding than a simple response to a diagnostic question. The question we have addressed is can we use that information to make accurate predictions of which misconception a student has?

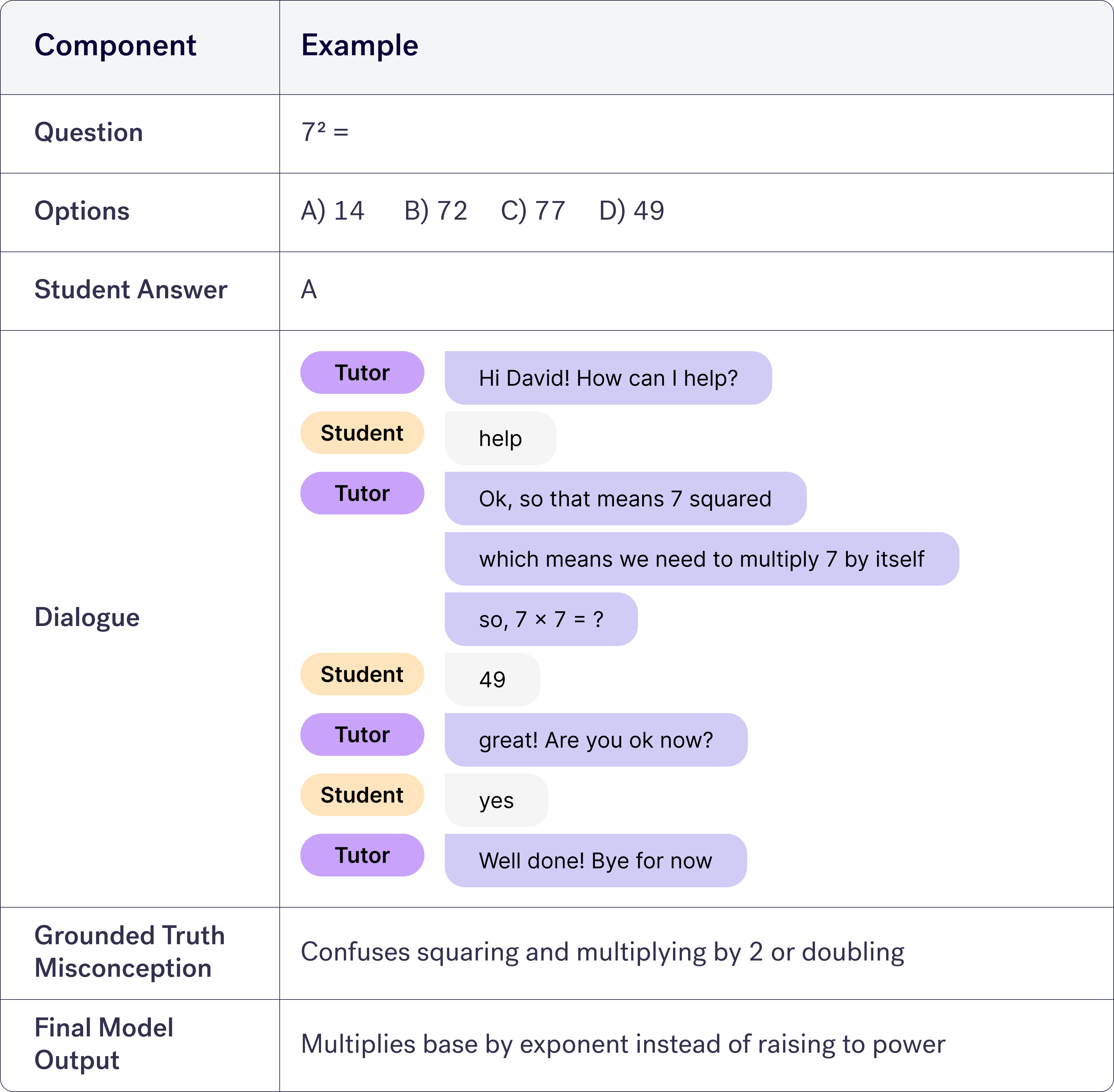
In this work, we used dialogues between students and human tutors, which has occurred after a student attempted a question and chose an incorrect answer. To get ground-truth labels, a tutor labelled how likely it is that the student has a specific misconception after the tutoring session had completed.
For this we compiled a dataset of 922 student-tutor dialogues, where the tutor has said with high confidence that the student has a specific misconception. In this dataset there are 546 unique misconceptions, resulting in a very sparsely labelled dataset.
When splitting the data into datasets for training and evaluating we were careful to split the dataset by misconceptions to truly test that the model can generalise to new unseen misconceptions. An example of a student-tutor dialogue is provided below.
We built a three-stage model comprising of a generation stage, a retrieval stage, and a reranking stage.
The first generation stage takes the input question, answer chosen by the student, and the student-tutor dialogue and uses an LLM to generate a plausible misconception that the student may have. The second stage uses an embedding model to compare the generated plausible misconception against a library of possible misconceptions that could exist for a student. From this we can identify the top K misconception hypothesis that the student has. Following this, stage 3 uses an LLM to rerank the top K misconception hypothesis to produce the model’s final prediction of which misconception the student has.
Each of the LLMs in stages 1 and 3 can also be fine-tuned using LoRA adapters. The flow through the three stages is shown in the diagram below.

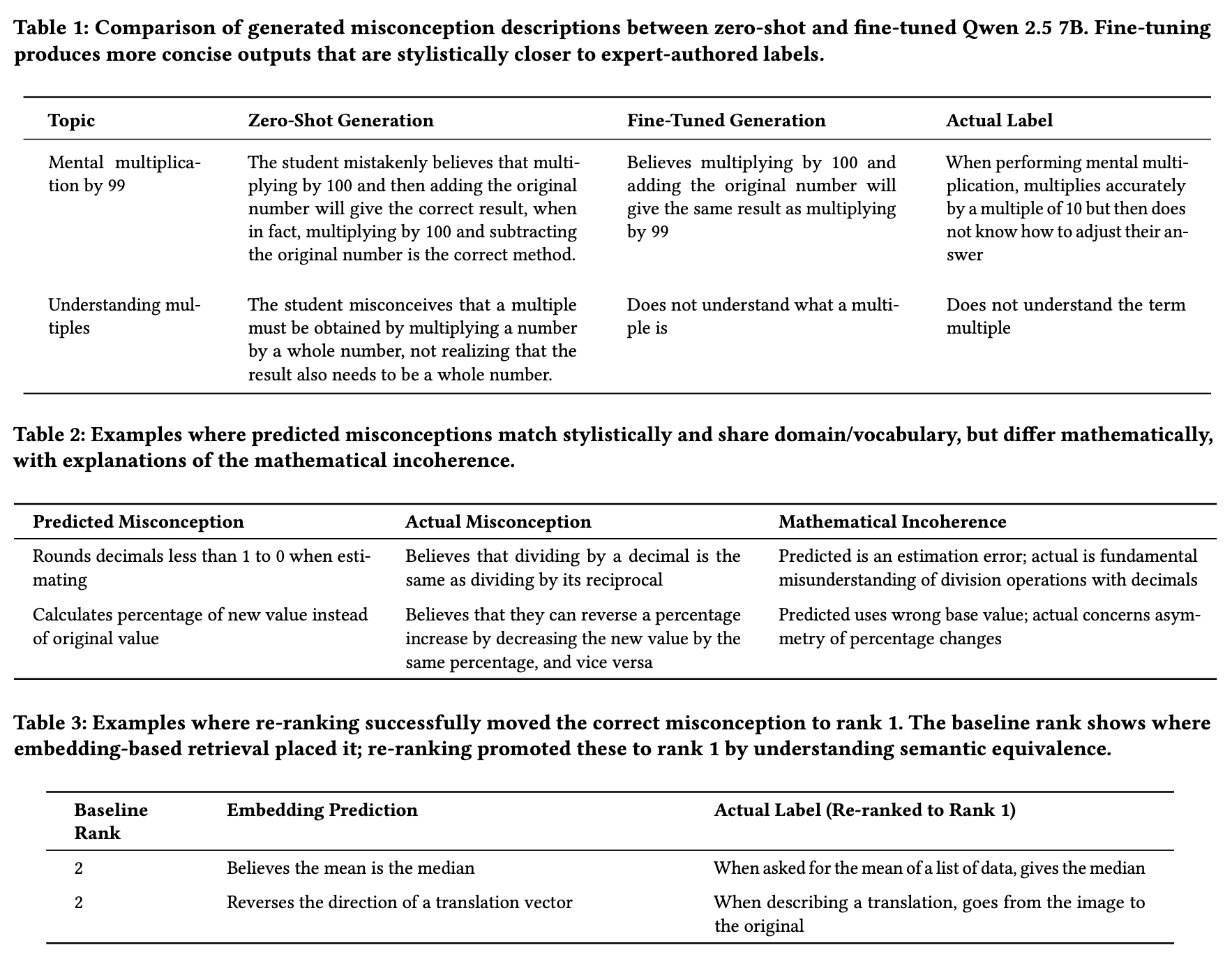
We found that stage 1, i.e., the generation stage, is good at generating misconceptions that capture the misconception the student has demonstrated in the student-tutor dialogue. It closely aligns with the ground truth actual label.
We also found that fine-tuning an open source model creates a model that generates misconceptions that are more stylistically similar to the types of misconceptions written at Eedi.
When using the reranking stage we also found that it improves the ordering of predicted misconceptions such that the true misconception occurs higher in the ordering and in many cases promotes the true misconception to rank 1.
We also conducted an ablation study of each part of our model pipeline with 3 different base models: Claude, Llama, and Qwen to show how the performance varies across larger closed source LLMs, smaller open source LLMs and fine-tuned LLMs. One evaluation metric we used to compare different models is MAP@k, which measures how close to rank 1 the model predicted the true misconception at.
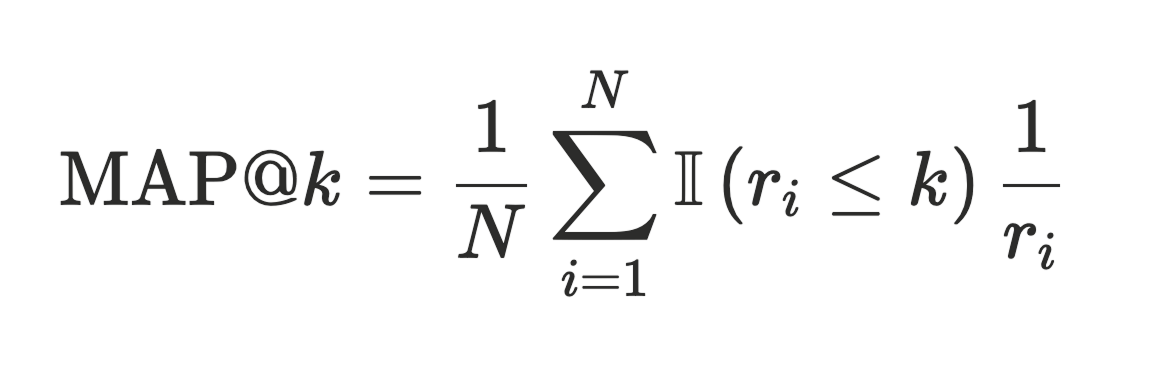
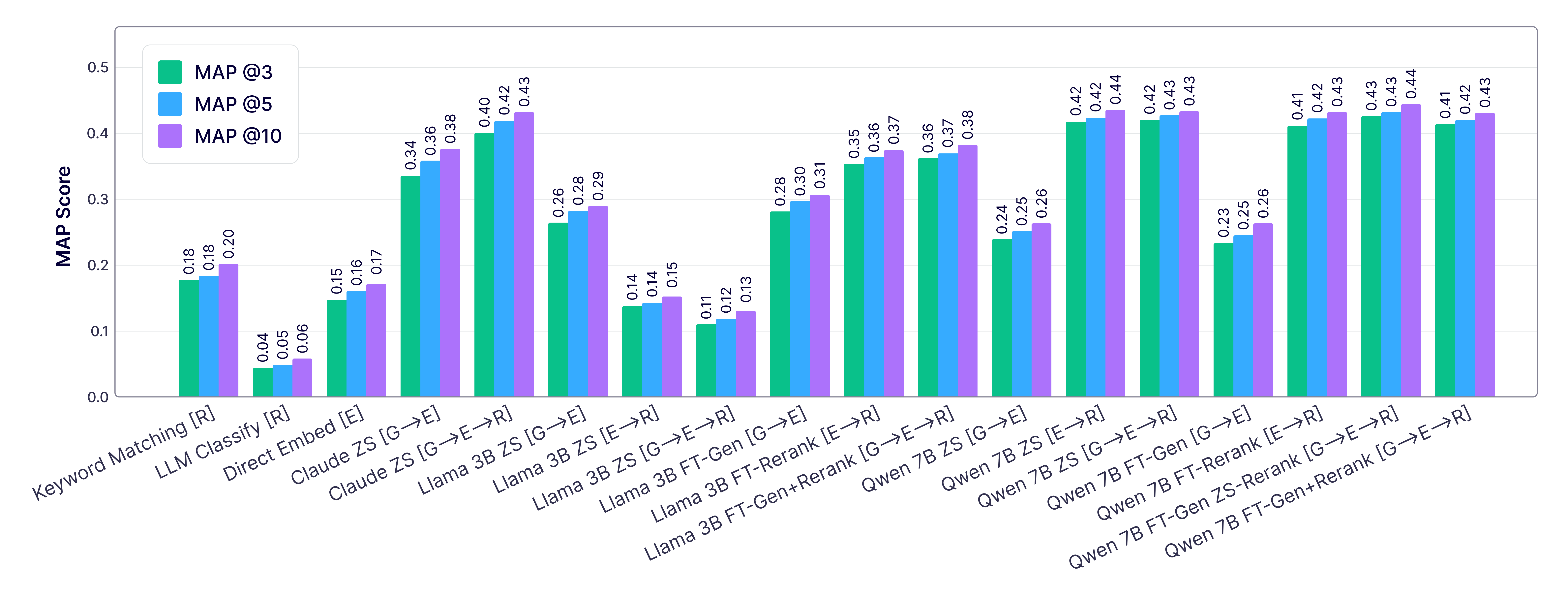
From this we found that smaller open source models can perform similarly to larger close source models at predicting students misconceptions from student-tutor dialogues. We also found that fine-tuning can improve smaller open source model performance.
We also found that our approach significantly out performs baselines including keyword matching, directly trying to classify using a single LLM model, and classifying using only an embedding model.
Being able to more accurately identify misconceptions has a real benefit in allowing educators to resolve them before the students error compounds. This work presents a novel approach to identifying misconceptions from dialogue and steps forward from gaining an indication of a student having a misconception to identifying misconceptions from a richer data source.
This approach has shown to work well at identifying the specific misconception a student holds from a student-human tutor dialogue. With the rise of AI tutors this type of model can feed into the tutoring process to provide deeper insights to the AI tutor on the students current misconceptions. Further we are interesting in extending this work to identifying misconceptions from input data sources that are less time consuming for a student so that we don’t need the full dialogue with a tutor.
The full paper is available here: Misconception Diagnosis From Student-Tutor Dialogue: Generate, Retrieve, Rerank
This work was also presented at the NTO’s LAK workshop on AT Annotation and teacher Analytics and has been accepted at the Festival of Learning 2026 in June in Seoul, Korea.